Indonesian Language Model
Lingua
NLP (Natural Language Processing) has been proven useful for many industrial practitioners to gain insight and automate human-intensive labor in order to bring a better experience for their customers. Chatbot to quickly reply customers’ inquiries and free text search engine to help customers express their intent towards our product in more flexible way are a few examples of the use cases.
When dealing with text data, the representation of the text itself is one of the central components to build NLP applications. Recent state-of-the-art of text representations have been powered by word2vec and its variants that were first popularised by Mikolov et al. 2013. However, as an Indonesian-based technology company, Traveloka deals with a high volume of Indonesian text. Due to the fact that Indonesian is considered as one of the low-resource languages, not much work has been done in text representation for this language.
Language Model
It is tempting for us to build word2vec embedding from our own corpus that later can be used by the whole company. However, recent study from Wendlandt et al.2018 and Antoniak et al.2018 show that word dense representations may suffer from instabilities measured by their closeness of their neighbours. An interesting fact coming from Wendlandt et al.2018 states that the instabilities do not affect most of the downstream tasks and shows that LSTM is quite robust to handle the instabilities. They measure it by training an LSTM model in POS Tagging task with pre-trained word embedding that shows instabilities. Coming from those studies, we are looking deeper to the representation resulted from the LSTM model instead of the embedding itself. Our reasoning is strengthened further by Howard, J and Ruder, S., 2018 with their new technique of transfer learning for classification task. Their new framework works by training the LSTM + word embedding in language model fashion in large size corpus such as wikipedia, transfer the trained weight into specific corpus and train the classifier as the final steps.
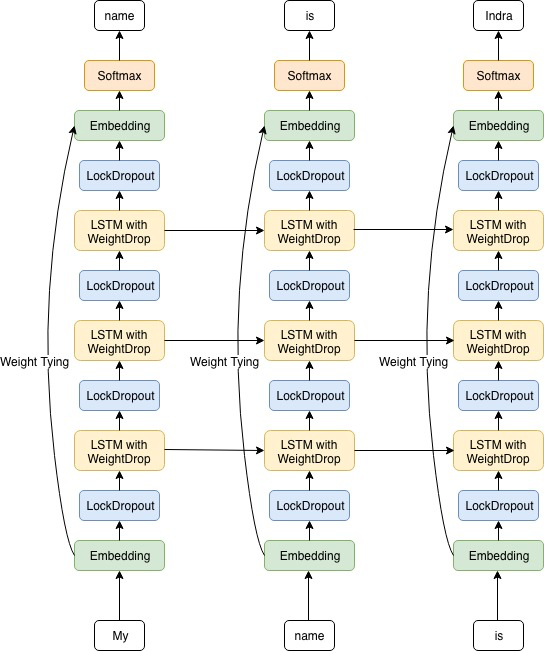
Following Howard, J and Ruder, S., 2018, we chose AWD LSTM (without further fine-tuning and cache pointer) as the current state-of-the-art in language model. The first step of ULMFiT is to build a language model trained from generic corpus such as wikipedia and then later to transfer the weight for more specific corpora. However, due to the lack of baseline, we decided to divide the experiment into several phase: Building the language model directly on our conversational dataset. Training it on Indonesian wikipedia and transferring the weight to train the model with our conversational dataset. The goal of this experiment is to compare the significance of transfer learning with the one that is trained from scratch.
Furthermore, it is common practice in NLP to use pre-trained word embedding to improve accuracy on several tasks. In this experiment we will use fasttext as our pre-trained word embedding for language modelling task.
AWD LSTM
The authors of AWD LSTM paper propose some optimization and regularization techniques which empirically improve the performance of LSTM language models:
NT-ASGD
While momentum SGD is usually better than traditional SGD for training deep neural networks in general, for neural language modeling task, traditional SGD is better than momentum SGD and other algorithms. One variant of it is Averaged SGD (ASGD) which is the same as SGD until some iteration T, but in the following iterations ASGD will update the weights with the average of weight updates of some previous iterations.
NT-ASGD is similar to ASGD, but instead of always using the average to update the weights, it will only do it when the validation metric fails to improve for multiple cycles. In other cases NT-ASGD will be the same as traditional SGD.
Weight-dropped LSTM
Dropout is a popular choice of regularization technique for neural networks. However, it cannot be used for LSTM when an optimized black box LSTM implementation, such as NVIDIA’s cuDNN LSTM, is used. To solve that, DropConnect can be used as an alternative of Dropout. While Dropout randomly set activation units to zero, DropConnect randomly set connection weights to zero. In this way, the dropout operation can be applied once to the weight matrices, before the forward and backward pass. So, any black box LSTM implementation can be used.
Similar to variational dropout, the same individual dropped weights remain dropped over all timesteps, i.e. the entirety of forward and backward pass.
Variational Dropout
Variational Dropout samples a binary dropout mask once and then it is used for all repeated connections within the entirety of forward and backward pass. Variational Dropout is not only used for LSTM weights (as described in section (2) before), but also used for all dropout connections. For example, the same dropout masks are used for all inputs and outputs of the LSTM.
Embedding Dropout
This technique is equivalent to performing variational dropout on the connection between the one-hot embedding and the embedding lookup. Variable-length backpropagation sequences Instead of having a fixed length of backpropagation sequences, the sequence length is randomly selected for each entirety of forward and backward pass. The learning rate is then rescaled depending on the length of the resulting sequence.
Weight tying
One way to reduce the number of model’s parameters is to share the weights between the embedding and the softmax layer after the LSTM. This technique is empirically shown to have a better performance than that of the standard LSTM language model.
Independent embedding size and hidden size
In contrast to most LSTM language models, AWD LSTM model uses different sizes for embedding and hidden states.
L2 Regularization
L2 regularization is used on the individual unit activations and on the difference in outputs of an RNN at different timesteps.
Data Gathering
Conversational Dataset
One of the greatest things about training language model is that even though the algorithm still fall into supervised machine learning model, we can gather the label without strenuous effort.
In this phase we decided to work with our conversational data, i.e. the conversation between our customer service agents and our customers, to build the language model as a supporting building block for our other project.
As we may well aware, dealing with user generated data is much more complex as we have more sparse data compared to a standard NLP corpora such as Wikipedia, WSJ, and so on. It is due to typos, abbreviation, and excessive uses of punctuations. To give an example, word “pembayaran” (“payment”) is registered in our corpora in 30 different forms (“pembyaran”, “pembayran”, “pembyran”, “pembayan”, “pembayaraan”, ….).
Before showing you the distribution of our data, we preprocessed our data using some scripts that we build in house. Some of them used to normalising the characters, converting some entities that are easily detected using simple regexes such as email, phone number, and url to their respective unique tokens (EMAIL, PHONE, URL, etc), normalising punctuations, and normalising some abbreviations.
The following is the distribution of our unique tokens from 10,000 feet:
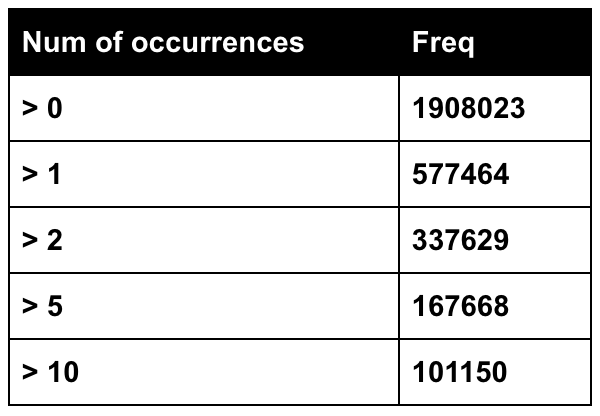
As you can see from the table above, initially our data consist of 1.9M++ unique tokens. After looking in the data further, we find out that more than half of our unique tokens are actually some “magic” numbers, typos, and other magical forms that we may not even understand without further context. From there we decided to remove the tokens with frequency less than 5 and 10 to reduce the number of word embedding matrix.
Wikipedia
We use wikimedia to download the latest version of Indonesian wikipedia dataset for our training data. The dumped XML data that is then extracted using wikiextractor, we tried to use Wikipedia parsing from gensim, but the result was not as good.
After the data has been extracted, we follow the work of WikiText by relying on MosesTokenizer to tokenize and normalize the words. We further tune the preprocessing by doing minimal work to remove unintended strings.
Below is the distribution of the wikipedia dataset that we use:

Language Model Training
To train language model, we prepare three different versions of a single dataset as cross validation datasets. Cross-validation is an important step for training machine-learning models in order to measure their stability towards the dataset. We generated the three different datasets once upfront and train it using different type of hyperparameters. We are currently measuring the performance through the validation dataset and not yet setting up a golden set. The way we measure the stability of the model is by analyzing the variance of the model performance throughout those chunk of datasets.
Training the language model, especially with a significant amount of vocabularies requires a lot of computational resources while calculating the softmax. In our implementation, we are using Adaptive Softmax to cut off the cost of the calculation and hence speeding up the training process and safe a number of GPU memory. Further, we train the model with a single instance of 2 P100 GPUs and run every batch steps on those GPUs in parallel. The best model was obtained after 6 days of training on our conversational dataset and around 10 days ++ for our wikipedia dataset. Afterward, the model started to overfit by showing a decreasing performance on validation set. One note that we want to convey is that in this moment, we have not yet tried hyperparameter tuning due to time constraints and still relying on default parameters provided on AWD LSTM paper.
We evaluated our models based on two different metrics, cross-entropy loss and perplexity. Different from other tasks such as classification where we can measure the accuracy through F1 Score, precision and recall, we measure the performance of language model from the cross-entropy loss directly. Perplexity is essentially the probability that assigned by the language model (from softmax layer), normalized by the number of words.
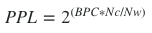
For brevity, we hereby give you the best scores of a set of experiments that we ran. All of the following scores are given based on the aforementioned validation datasets.
Experiment on Conversational dataset
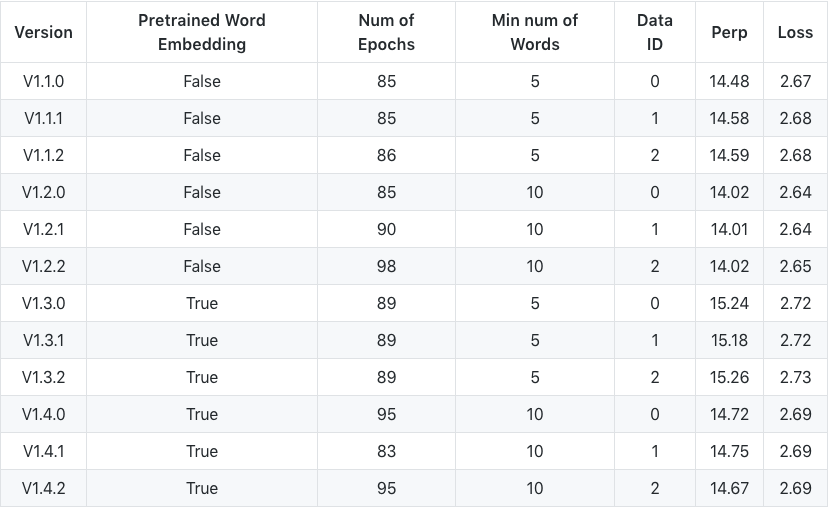
Experiment on id-wikipedia
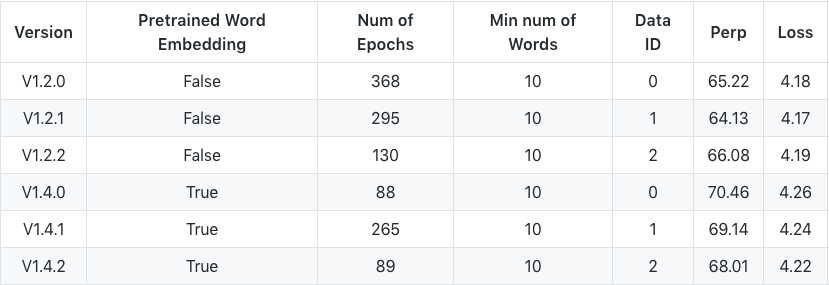
During the training process, we made the following observations:
- Evidently, increasing the minimum number of words boost our model by reducing both the loss and perplexity by 0.04. This explains the importance of removing low-frequency words from dictionary.
- We also observe the uses of word embedding (from fastText) leads to a lower performance.
- AWD-LSTM performs consistently across the board. It varies quite a bit on the perplexity side, but not that differ from loss point of view.
All in all, AWD LSTM shows a consistent performance and shows stability in two completely different datasets (conversational and id-wikipedia dataset) for low-resource language. This marks a positive result in our effort to create a high-quality language model that will be used as a baseline to our transfer learning experiments later.
Future Works
It is true that we are still facing a big size of vocabularies that is introduced by typos in our corpus, but worry not we are on our way to attack that problem. As a snippet, here we are giving you the performance of latest experiment
Experiment on Conversational dataset

We managed to improve the loss by 0.1 and down to 2 points in perplexity.
Final Thoughts
During this experiment, here are a few takeaways that might be helpful for other practitioners.
First, be diligent on your data, especially in natural language problem. The real word data may introduce more problems than you anticipate, especially if you decide to tackle the problem in word level manner. You may need to invest more in pre-processing to clean up the data. It may seem common in any NLP tasks, but we can’t stress it enough the importance of handling typos inside your corpus. The other way around for handling typo is by modifying your deep learning architecture and let the model handle the typos by itself.
Second, cross validation is important for machine learning practitioners to understand as a way to measure the stability of your model. Though in deep learning case it is quite expensive to run cross validation, you can always reduce the number of experiments to run so that it fits your budget.
Lastly, training in parallel is one of the important key to train a big deep learning model. In this case, we gained a speed-up of 2x the normal training time by using 2 GPUs.